No one likes clickbait headlines yet they seem to be everywhere. It would be great if a computer model could figure out if a headline is clickbait or not so that we don’t have to waste our time with those garbages. In this post, I’ll show you how we can build a simple but accurate model for detecting whether a headline is clickbait or not.
Dataset
First, download the dataset from here. I’ll quote the original authors of this dataset
The directory contains two files each consisting the headlines of 16,000 articles. Both files are compressed using gzip, and each line in the decompressed files contains one article headline. The clickbait corpus consists of article headlines from ‘BuzzFeed’, ‘Upworthy’, ‘ViralNova’, ‘Thatscoop’, ‘Scoopwhoop’ and ‘ViralStories’. The non-clickbait article headlines are collected from ‘WikiNews’, ‘New York Times’, ‘The Guardian’, and ‘The Hindu’.
Extract the files from the two archives. You should have two files in your folder. I’ll be using Jupyter notebook to write and execute the code.
Let’s import some libraries
1
2
3
4
5
6
7
import pandas as pd
import os
import re
import matplotlib.pyplot as plt
from matplotlib import style
style.use("ggplot")
%matplotlib inline
Next we’ll read those two files. Since the files contain blank lines as well, we’ll discard those and for the rest of the lines, we strip them i.e. remove whitespace from beginning and end of the line.
1
2
3
4
5
6
7
def read_lines(path):
with open(path, encoding="utf8") as f:
return [l.strip() for l in f if len(l.strip()) > 0]
clickbaits = read_lines("./clickbait_data")
nonclickbaits = read_lines("./non_clickbait_data")
len(clickbaits), len(nonclickbaits)
(15999, 16001)
You should get the same number as I got.
Now to create a labeled dataset we need to run the following. All we are doing is concatenating two lists clickbaits and nonclickbaits into a single list titles. In the second line, we create labels for our data. 1 indicates that it is clickbait and 0 indicates it is not. So we generate a list of 1s via [1] * len(clickbaits). This will create a list of size len(clickbaits) where each element is 1. We do the same thing and generate a list of 0s and finally concatenate them into a single list called labels.
1
2
titles = clickbaits + nonclickbaits
labels = [1] * len(clickbaits) + [0] * len(nonclickbaits)
We also split the data into training and testing set.
1
2
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(titles, labels)
Rule Based Model
Whenever I think of clickbaits, usually these patterns come to my head
- 45 facts about X you never knew. You won’t believe number 53!
- Why you should do X
- … and here is why
and others
So let’s create a simple rule based model. Usually, these headlines start with Wh words like When, How, Why or with digits. So our first model will simply assign a headline as clickbait if it starts with Wh words or digits.
First let’s create a helper function to print prediction results.
1
2
3
4
from sklearn.metrics import classification_report, accuracy_score
def print_pred_report(y_true, y_pred):
print("accuracy = ", accuracy_score(y_true, y_pred))
print(classification_report(y_true, y_pred))
We’ll use regular expression to check if the title starts with digit or Wh word. If it does then we’ll classify it as a clickbait.
1
2
3
4
5
# simple model based on whether the title starts with "wh" words or digits
starts_wh_re = re.compile(r"^(What|How|Why|When|Which|Who|Where)", re.I)
starts_digit_re = re.compile(r"^\d+")
preds = list(map(lambda title: starts_wh_re.match(title) != None or starts_digit_re.match(title) != None, x_test))
print_pred_report(y_test, preds)
1
2
3
4
5
6
7
8
9
accuracy = 0.7405
precision recall f1-score support
0 0.67 0.97 0.79 4016
1 0.94 0.51 0.66 3984
micro avg 0.74 0.74 0.74 8000
macro avg 0.80 0.74 0.73 8000
weighted avg 0.80 0.74 0.73 8000
Not bad for a simple rule based model but we can do better. The recall for class 1 i.e. clickbaits is quite low indicating it did not classify them as clickbait even though they were. Obviously, not all clickbaits start with Wh or digits so this is expected. Precision for nonclickbaits is also quite low with only 0.67.
Let’s improve this with a simple logistic regression model.
Logistic Regression Model
We’ll train a logistic regression model to classify the headlines. But first, we need to convert the headlines which are in textual format into numeric data so that the models can be trained and queried. For creating features from the text, we’ll use TfidfVectorizer. We also need to train this vectorizer so that it can learn the vocabulary (unique words in the given dataset), what score to assign to each word etc. Typically Tf-Idf gives more weight to less frequent words than frequent ones. Check these links for more info
- https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.TfidfVectorizer.html#sklearn.feature_extraction.text.TfidfVectorizer
- https://en.wikipedia.org/wiki/Tf%E2%80%93idf
Note that we are not doing any pre-processing on the words like stop word removal, stemming etc. but you could definitely try it out.
1
2
3
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer()
tfidf.fit(x_train)
Now that our vectorizer is trained, we can create our model and train it. For this demo we’ll just use LogisticRegressionCV with default parameters. You can try other models as well like MultinomialNB, SGDClassifier etc.
1
2
3
4
5
6
7
from sklearn.linear_model import LogisticRegressionCV
from sklearn.pipeline import make_pipeline
cls = LogisticRegressionCV()
cls.fit(tfidf.transform(x_train), y_train)
pipe = make_pipeline(tfidf, cls)
preds = cls.predict(tfidf.transform(x_test))
print_pred_report(y_test, preds)
1
2
3
4
5
6
7
8
9
accuracy = 0.9745
precision recall f1-score support
0 0.97 0.98 0.97 4066
1 0.98 0.97 0.97 3934
micro avg 0.97 0.97 0.97 8000
macro avg 0.97 0.97 0.97 8000
weighted avg 0.97 0.97 0.97 8000
97% accuracy! Nice. precision and recall of both classes are very good. But what did the model learn? What can we learn from what the model learned?
Model Analysis
To see what the model learned, we’ll use a library called eli5 which can help you visualize your models built with sklearn and few other libraries. Read its documentation at https://eli5.readthedocs.io/en/latest/ We just need to call show_weights function that will show the top 50 most influencing words for each category.
1
2
import eli5
eli5.show_weights(cls, top=50, vec=tfidf)

As we can see the common words are you, this, these, your, buzzfeed, 21, people, 17, 2015, we, things, 2016, how, 19, 23, my, adorable. See how many of these are pronouns and digits.
Now let’s see the predictions for each sentence and visualize the output.
1
2
3
4
5
from IPython.display import HTML, display_html
for idx in range(40):
print(x_train[idx], y_train[idx])
tbl = eli5.show_prediction(cls, x_train[idx], vec=tfidf)
display_html(HTML(tbl.data))
For each word, the green means the word has positive impact for the predicted category and the red means it has negative impact. The intensity of color determines the weight each of those words put in.
 Many of the headlines from clickbait articles
Many of the headlines from clickbait articles y=1 have these words with great influence: 23, worst, relationship, anyone, these, you whereas normal headlines seem to have words like the name of countries, fire, killed etc.
Finally, to see frequently used words in clickbaits and normal titles, let’s plot a couple of charts.
1
2
3
4
5
6
7
8
9
10
11
12
13
from collections import Counter
def plot_freq(sentences, n=40, title="Word frequency"):
words = [word.strip() for sentence in sentences for word in sentence.lower().split()]
c = Counter(words)
wc = pd.DataFrame(c.most_common(n), columns=["word", "count"])
plt.figure(figsize=(20, 8))
plt.title(title)
plt.xticks(rotation=-45)
plt.bar(wc["word"], wc["count"])
plot_freq(clickbaits, title="Word frequency of top words in clickbait titles")
plot_freq(nonclickbaits, title="Word frequency of top words in clickbait titles")
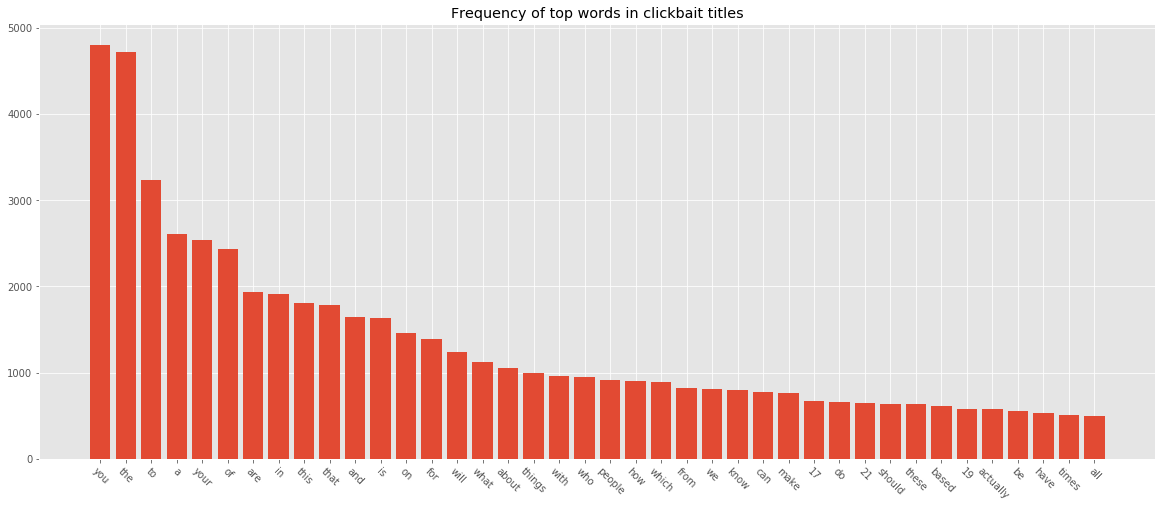
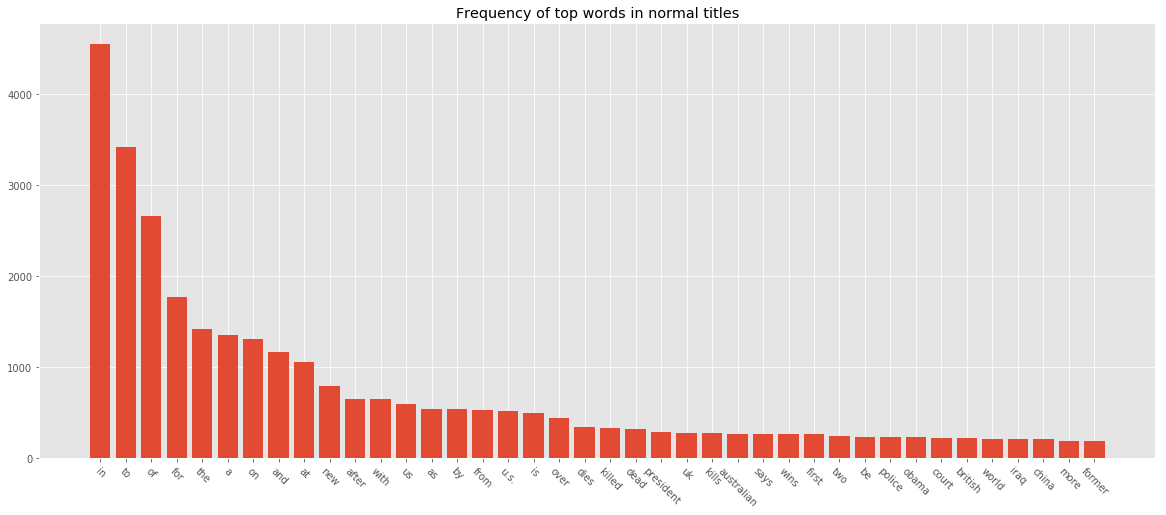 In normal headlines, a lot of top frequent words are stopwords like in, the etc. We can experiment with stopword removal to see what difference it makes. We can pass
In normal headlines, a lot of top frequent words are stopwords like in, the etc. We can experiment with stopword removal to see what difference it makes. We can pass stopwords="english" to TfidfVectorizer or provide our own list of stopwords and pass it.
Conclusion
We were able to correctly classify between clickbaits and normal headlines using a very simple logistic regression. Although the model performed really good in this dataset, it may or may not work in the wild. But I’m pretty sure that article headlines from Buzzfeed and similar websites, from where this dataset was compiled, will be correctly classified as clickbaits.




Comments