This article is Part 2 in a 2-Part Web Scraping with Python.
Introduction
In this post, we will build a simple scraper using requests and BeautifulSoup libraries. We’ll be using requests to send and receive HTTP requests and responses and use BeautifulSoup to parse the HTML content.
Let’s define our scraper. The scraper will scrape all the title, image and excerpt of articles posted in this blog. If you navigate to the home page, you’ll see that there are articles listed. Not all articles are listed in the same page so there is a pagination at the end to help navigate. The concepts that you’ll learn here can be applied to any other websites where the items are paginated.
The steps that our scraper will follow is shown below.
Here, seed url is the link to the home page of this blog. Then the scraper downloads the page, extracts the title, image and excerpt of each article and finds the link to “next” page. If link to “next” page exists, then it’ll repeat the steps otherwise it’ll exit.
Code
First, import the required libraries
1
2
3
4
import requests
from bs4 import BeautifulSoup
import json
from urllib.parse import urljoin
Now we’ll define our main loop of the scraper. Note that the functions in the main loop have not been defined yet.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
seed_url = "https://sanjayasubedi.com.np"
if __name__ == "__main__":
next_url = seed_url
articles = []
while next_url is not None:
print("Downloading {}".format(next_url))
html = download_page(next_url)
# create a beautifulsoup object from html text
soup = BeautifulSoup(html, "html.parser")
extracted_articles = extract_articles(soup)
print("Extracted {} articles".format(len(extracted_articles)))
# concatinate two list of articles
articles += extracted_articles
next_url = extract_next_url(soup)
save_articles(articles, "./articles.json")
print("Finished")
So first we assign a value to seed_url and also assign it to next_url. The while loop will repeat until the next_url contains some value. This is necessary so that if the scraper can’t find any links to crawl other than the seed_url, it will exit. So the scraper downloads the html content from the url using download_page function. Then we create a BeautifulSoup object and use it to extract articles using extract_articles function and also next url using extract_next_url function. For every articles extracted from a page, we add them to articles list so that once the loop is finished, it contains every article from all the pages that were scraped. Finally, we save the articles to a file using save_articles function.
For many simple and one-off scraping tasks, this approach is good enough. Of course, there is no error handling code here but apart from that this is mostly how it would be.
Now let’s implement the functions that we’ve used in the loop.
1
2
3
4
5
6
7
8
9
10
11
def download_page(url):
"""
downloads a page and returns its contents
:param url url to download
:returns content received from the url
"""
# download the web page
resp = requests.get(url)
# make sure that http status code is 200
assert resp.status_code == 200
return resp.text
download_page is a simple function that creates a HTTP GET request for the given url. We make sure that the HTTP response code is 200 i.e. everything as fine and there were no server errors like 404 Page not found. Finally we return the content downloaded.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def extract_articles(soup):
"""
extracts article title, image, and excerpt
:param soup beautifulsoup object
:returns a list of dict
"""
output = []
article_elements = soup.select("div.archive article")
for ele in article_elements:
title = ele.select_one("h2").text
excerpt = ele.select_one("p[itemprop=description]").text
image = urljoin(seed_url, ele.select_one("div.archive__item-teaser > img").get("src"))
output.append(dict(title=title, excerpt=excerpt, image=image))
return output
Next one is extract_articles function which takes in a BeautifulSoup object and returns a list of dicts containing title, excerpt and image. In BeautifulSoup you can use xpath or css selectors to find the elements. Here I’m using CSS selectors. .select function returns a list of elements that matches the particular selector whereas .select_one returns only one element. If there are multiple matches, then it returns the first one. If there are no matches, it returns None.
On your browser press Ctrl+Shit+I or right click and choose Inspect Element to open up the inspector in your browser. You can find that that all the articles are inside a div with class archive and each article is inside article tag. So we create a selector div.archive article which means find all elements with tag article that is inside a div with class archive. For more details on CSS selectors, visit this page http://htmldog.com/references/css/selectors/.
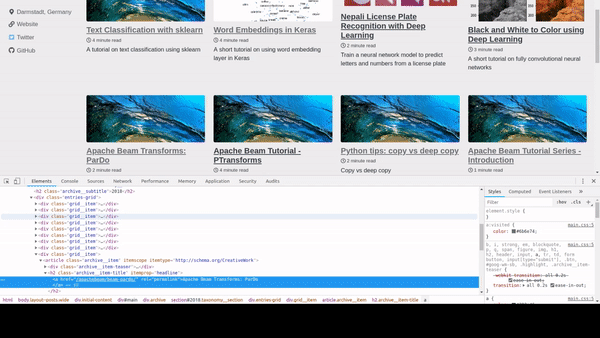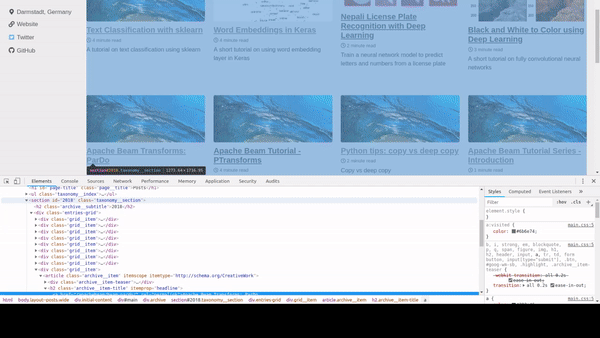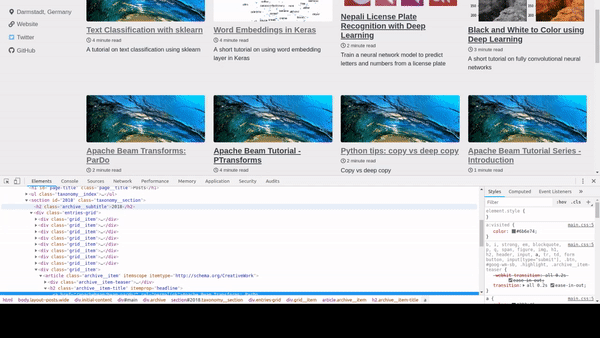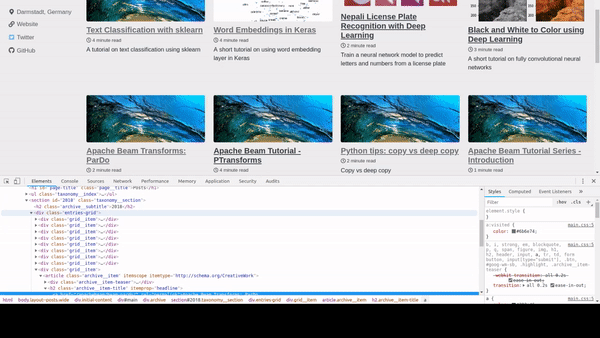 Now for each elements that are supposed to contain the articles, we extract title, excerpt and image. Once again, after inspecting a article block, we can see that the title is inside
Now for each elements that are supposed to contain the articles, we extract title, excerpt and image. Once again, after inspecting a article block, we can see that the title is inside h2 tag so we call select_one with the selector h2.
For excerpt, we can see that it is in a p tag which also has an attribute called itemprop and its value is set to description, so create a selector p[itemprop=description] that means find all elements with p tag that has itemprop attribute and its value is set to description. If there are other p elements with out that itemprop attribute with description value, they won’t be selected.
For image, we know that it is in an img tag which is a direct child of a div with class archive__item-teaser, so we create a selector div.archive__item-teaser > img (note the > since img is direct child of the div) and use get function to retrieve src attribute of img. You might have noticed that the value in src does not contain absolute link, so we need to make it absolute which can be done by calling urljoin function.
Finally we create a dictionary and append it to output and return once all articles are processed.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def extract_next_url(soup):
"""
extracts next url from the pagination if it exists
:param soup beautifulsoup object
:returns url of next page or None
"""
a_elements = soup.select("nav.pagination a")
for ele in a_elements:
# classes assigned to this element, either empty list or actual classes
classes = ele.get("class") or []
# find a with text "Next" and its classes is not one of disabled
if ele.text == "Next" and "disabled" not in classes:
return urljoin(seed_url, ele.get("href"))
return None
extract_next_url function extracts next url to scrape. Here, we are trying to find an element with tag a inside nav. For each a elements, we check if it contains text Next and if it does not have a class disabled. This logic is specific to my blog. For other websites it will be different, so you’ll have to come up with your own logic. Try going to the last page and see what happens to the Next button. Some website completely remove the button, some websites just hide it so users can’t see it but it is present. You need to make sure that you covered all edge cases. Otherwise, the loop will run infinitely!
1
2
3
4
5
6
7
8
def save_articles(articles, filepath):
"""
saves articles to a json file
:param article a list of dict
:param path of file to save
"""
with open(filepath, "w") as f:
json.dump(articles, f, indent=4)
Finally, the save_articles function. It just dumps the list of articles in a JSON format.
Here is what I got when I ran the program.
1
2
3
4
5
Downloading https://sanjayasubedi.com.np
Extracted 12 articles
Downloading https://sanjayasubedi.com.np/page2/
Extracted 4 articles
Finished
And the file contains
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
[
{
"title": "\nPredicting if a headline is a clickbait or not\n\n",
"excerpt": "Learn how to classify if a headline is a clickbait or not\n",
"image": "https://sanjayasubedi.com.np/assets/images/teaser.jpg"
},
{
"title": "\nShort Tutorial on Named Entity Recognition with spaCy\n\n",
"excerpt": "A simple and minimal example showing how to detect named entities in an unstructured text\n",
"image": "https://sanjayasubedi.com.np/assets/images/teaser.jpg"
},
{
"title": "\nText Classification with sklearn\n\n",
"excerpt": "A tutorial on text classification using sklearn\n",
"image": "https://sanjayasubedi.com.np/assets/images/teaser.jpg"
},
{
"title": "\nWord Embeddings in Keras\n\n",
"excerpt": "A short tutorial on using word embedding layer in Keras\n",
"image": "https://sanjayasubedi.com.np/assets/images/deep-learning/word-embeddings/glove_airbnb2_sbd_01.png"
},
{
"title": "\nNepali License Plate Recognition with Deep Learning\n\n",
"excerpt": "Train a neural network model to predict letters and numbers from a license plate\n",
"image": "https://sanjayasubedi.com.np/assets/images/deep-learning/nepali-license-plate/samples.png"
},
{
"title": "\nBlack and White to Color using Deep Learning\n\n",
"excerpt": "A short tutorial on fully convolutional neural networks\n",
"image": "https://sanjayasubedi.com.np/assets/images/deep-learning/bw-to-color/data-pair.png"
},
...
]
Note the \n characters, they indicate a new line character and there might be whitespaces around the text you extracted. These can be removed by calling strip() function on the string e.g. new_title = title.strip()
Next Steps
We wrote a simple scraper to extract article contents. But many things are missing like error handling. What happens if we are scraping 10th page and suddenly there is an error. Our program will crash and already extracted articles will also be lost. Should we retry? Should we save often? What if the server blocks our IP for making too many requests? What if you have 10,000 pages to scrape and each page takes 1 second, you’ll have to wait almost 3 hours. In the next post we’ll improve our scraper and solve some of these issues.
This article is Part 2 in a 2-Part Web Scraping with Python.




Comments