This article is Part 3 in a 5-Part Understanding Transformers Architecture.
Introduction
In this post we’ll implement the Transformer’s Encoder layer from scratch. This was introduced in a paper called Attention Is All You Need. This layer is typically used to build Encoder only models like BERT which excel at tasks like classification, clustering and semantic search.
The figure below (taken from the paper above) shows the architecture of a Encoder network.
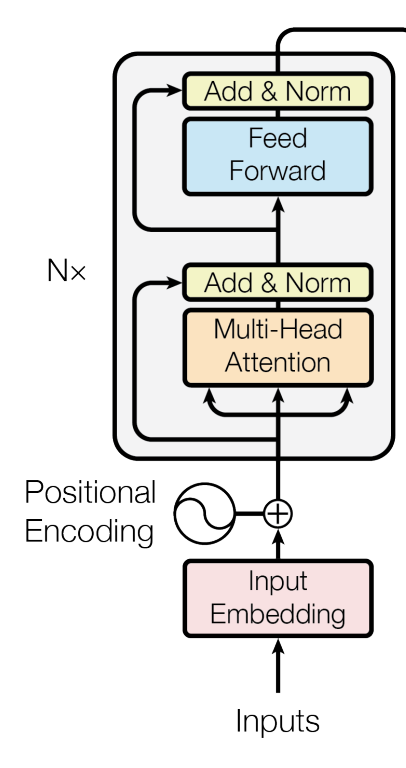
An encoder network consists of N Encoder layers. Each Encoder layer consists of a MultiHeadAttention layer, followed by LayerNorm. The outputs from the LayerNorm is then passed to a Feed Forward network which is then again passed through another LayerNorm. The outputs from the Encoder network can then be passed to futher layers depending on the task. For example, for a sentence classification task, we can pass the output embeddings to a classification head to produce class probabilities.
Implementation
Let’ start by defining a single Encoder layer. As seen in the figure above, we need a MutliHeadAttention layer and couple of LayerNorm layers and a Feed Forward block.
The Feed Forward block is mentioned in section 3.3 of the paper. They call it “Position-wise Feed-Forward Networks”. This is a simple “block” consisting of a Linear -> ReLU -> Linear layers. The output of the first Linear layer is defined by the parameter dim_feedforward and the authors used a 2048 as its value. The output of the last Linear layer is same as the input embedding dimension.
In code it looks like this:
1
2
3
4
5
torch.nn.Sequential(
torch.nn.Linear(in_features=embed_dim, out_features=dim_feedforward, bias=True),
torch.nn.ReLU(),
torch.nn.Linear(in_features=dim_feedforward, out_features=embed_dim, bias=True)
)
We also need a couple of Dropout layers. Dropout layers are not shown in the figure but the authors mention about their usage in section 5.4 of the paper. They apply dropout to output of each sub-layer before it is added to the sub-layer input and normalized.
Now we know everything there is to about an Encoder layer. The code below shows the implementation of EncoderLayer.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# import some libraries we'll probably use
import numpy as np
import pandas as pd
import torch
# just used for plotting
from lets_plot import *
LetsPlot.setup_html()
class EncoderLayer(torch.nn.Module):
def __init__(self, embed_dim: int, n_heads: int, dim_feedforward: int = 128, dropout=0.1):
super().__init__()
self.embed_dim = embed_dim
self.n_heads = n_heads
self.mha = torch.nn.MultiheadAttention(embed_dim=embed_dim, num_heads=n_heads, batch_first=True, bias=True)
self.layer_norm1 = torch.nn.LayerNorm(normalized_shape=embed_dim)
self.layer_norm2 = torch.nn.LayerNorm(normalized_shape=embed_dim)
# section 5.4
# apply dropout to output of each sublayer before it is added to sublayer's input
self.dropout1 = torch.nn.Dropout(p=dropout)
self.dropout2 = torch.nn.Dropout(p=dropout)
# section 3.3 in paper
self.position_wise_ff = torch.nn.Sequential(
torch.nn.Linear(in_features=embed_dim, out_features=dim_feedforward, bias=True),
torch.nn.ReLU(),
torch.nn.Linear(in_features=dim_feedforward, out_features=embed_dim, bias=True)
)
Now let’s focus on the forward method of the EncoderLayer class.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def forward(self, x, src_key_padding_mask=None, src_mask=None):
# x.shape = (batch_size, seq_len, embed_dim)
# src_key_padding_mask = (bs, seq_len), True value indicates it should not attend
# src_mask.shape = (bs, seq_len, seq_len) of dtype torch.bool, True value indicates it shouldn't attend
attn_output, attn_weights = self.mha(x, x, x, key_padding_mask=src_key_padding_mask, attn_mask=src_mask)
# dropout and residual connection
x = x + self.dropout1(attn_output)
x = self.layer_norm1(x)
projection = self.position_wise_ff(x)
# dropout and residual connection
x = x + self.dropout2(projection)
# layer norm
x = self.layer_norm2(x)
return x
As mentioned above, we first pass the input embeddings x through MHA layer. We then apply the dropout to the output of MHA and then add it with the original input embedding. Then this is passed to the first LayerNorm layer. Then we again pass this to the feed-forward block, apply the drop out, add to residual connection and pass it through the second LayerNorm layer. We finally return the final embeddings.
I’ve already covered about masking in the previous post so I will not go over them again here.
Now that we have a Encoder layer, let’s create another class to create a Encoder network. This class is just a simple wrapper that contains N different Encoder layers.
1
2
3
4
5
6
7
8
9
10
11
12
13
from copy import deepcopy
class Encoder(torch.nn.Module):
def __init__(self, encoder_layer, num_layers: int):
super().__init__()
layers = []
for _ in range(num_layers):
layers.append(deepcopy(encoder_layer))
self.layers = torch.nn.ModuleList(layers)
def forward(self, x, src_key_padding_mask=None, src_mask=None):
for layer in self.layers:
x = layer(x, src_key_padding_mask=src_key_padding_mask, src_mask=src_mask)
return x
Pytorch vs Our
To compare our implementation against Pytorch’s implementation, let’s build a text classification model and compare the performance. The TextClassifier class below implements a simple text classification model. It accepts an encoder parameter to try out different Encoder implementation. I’ve also copied an implementation of Positional Embedding from the link I’ve shared as a comment in the code.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
import math
class PositionalEncoding(torch.nn.Module):
# source: https://uvadlc-notebooks.readthedocs.io/en/latest/tutorial_notebooks/tutorial6/Transformers_and_MHAttention.html#Positional-encoding
def __init__(self, embed_dim, max_len=256):
super().__init__()
# create a matrix of [seq_len, hidden_dim] representing positional encoding for each token in sequence
pe = torch.zeros(max_len, embed_dim)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # (max_len, 1)
div_term = torch.exp(torch.arange(0, embed_dim, 2).float() * (-math.log(10000.0) / embed_dim))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe, persistent=False)
def forward(self, x):
x = x + self.pe[:, :x.size(1)]
return x
class TextClassifier(torch.nn.Module):
def __init__(self, vocab_size: int, embed_dim: int, num_classes: int, encoder: torch.nn.Module, max_len):
super().__init__()
self.positional_encoding = PositionalEncoding(embed_dim=embed_dim, max_len=max_len)
self.embedding = torch.nn.Embedding(num_embeddings=vocab_size, embedding_dim=embed_dim, padding_idx=0)
self.encoder = encoder
self.fc1 = torch.nn.Linear(in_features=embed_dim, out_features=128)
self.relu = torch.nn.ReLU()
self.final = torch.nn.Linear(in_features=128, out_features=num_classes)
def forward(self, input_ids: torch.Tensor, src_key_padding_mask=None, **kwargs):
# inputs: (bs, seq_len)
# embeddings: (bs, seq_len, embed_dim)
embeddings = self.get_embeddings(input_ids)
attn = self.encoder(embeddings, src_key_padding_mask=src_key_padding_mask)
# take the first token's embeddings i.e. embeddings of CLS token
# cls_token_embeddings: (bs, embed_dim)
cls_token_embeddings = attn[:, 0, :]
return self.final(self.relu(self.fc1(cls_token_embeddings)))
def get_embeddings(self, input_ids):
return self.positional_encoding(self.embedding(input_ids))
Click to expand dataset processing code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
import datasets
from transformers import AutoTokenizer
original_tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
news_ds = datasets.load_dataset("SetFit/bbc-news", split="train")
# train a new tokenizer with limited vocab size for demo
tokenizer = original_tokenizer.train_new_from_iterator(news_ds['text'], vocab_size=1000)
def tokenize(batch):
return tokenizer(batch['text'], truncation=True)
ds = news_ds.map(tokenize, batched=True).select_columns(['label', 'input_ids', 'text']).train_test_split()
class_id_to_class = {
0: "tech",
1: "business",
2: "sports",
3: "entertainment",
4: "politics",
}
num_classes = len(class_id_to_class)
Now that we have necessary classes, let’s create two models.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
embed_dim = 128
n_head = 8
dim_feedforward = 256
num_layers = 2
vocab_size = tokenizer.vocab_size
max_length = tokenizer.model_max_length
# pytorch
torch_encoder_layer = torch.nn.TransformerEncoderLayer(
d_model=embed_dim,
nhead=n_head,
dim_feedforward=dim_feedforward,
dropout=0.1,
batch_first=True,
norm_first=False,
)
torch_encoder = torch.nn.TransformerEncoder(
encoder_layer=torch_encoder_layer, num_layers=num_layers
)
# my
my_encoder_layer = EncoderLayer(
embed_dim=embed_dim, n_heads=n_head, dim_feedforward=dim_feedforward, dropout=0.1
)
my_encoder = Encoder(encoder_layer=my_encoder_layer, num_layers=num_layers)
torch_classifier = TextClassifier(
vocab_size=vocab_size,
embed_dim=embed_dim,
num_classes=num_classes,
encoder=torch_encoder,
max_len=max_length,
)
my_classifier = TextClassifier(
vocab_size=vocab_size,
embed_dim=embed_dim,
num_classes=num_classes,
encoder=my_encoder,
max_len=max_length,
)
def get_model_param_count(model):
return sum(t.numel() for t in model.parameters())
print(f"My classifier params: {get_model_param_count(my_classifier):,}")
print(f"Torch classifier params: {get_model_param_count(torch_classifier):,}")
1
2
My classifier params: 410,117
Torch classifier params: 410,117
Both the models have 410,117 number of parameters. Below I’ve defined a training loop. One important part is in the collate function where we pad the input_ids and then create key_padding_masks as follows.
1
2
3
input_ids = torch.nn.utils.rnn.pad_sequence(input_ids, batch_first=True, padding_value=0)
# create a boolean key padding mask by checking if input_id == 0 i.e padding_value
key_padding_masks = input_ids == 0
Click to expand training loop code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
from torch.utils.data import DataLoader
import time
def collate_fn(batch):
labels = []
input_ids = []
for row in batch:
labels.append(row['label'])
input_ids.append(torch.LongTensor(row['input_ids']))
input_ids = torch.nn.utils.rnn.pad_sequence(input_ids, batch_first=True, padding_value=0)
# create a boolean key padding mask by checking if input_id == 0 i.e padding_value
key_padding_masks = input_ids == 0
labels = torch.LongTensor(labels)
input_ids = torch.Tensor(input_ids)
return {"labels": labels, "input_ids": input_ids, "src_key_padding_mask": key_padding_masks}
train_dl = test_dl = DataLoader(ds['train'], shuffle=True, batch_size=32, collate_fn=collate_fn)
test_dl = DataLoader(ds['test'], shuffle=False, batch_size=32, collate_fn=collate_fn)
def train(model: torch.nn.Module, train_dl, val_dl, epochs=10) -> list[tuple[float, float]]:
optim = torch.optim.AdamW(model.parameters(), lr=1e-3)
loss_fn = torch.nn.CrossEntropyLoss()
losses = []
train_start = time.time()
for epoch in range(epochs):
epoch_start = time.time()
train_loss = 0.0
model.train()
for batch in train_dl:
optim.zero_grad()
logits = model(**batch)
loss = loss_fn(logits, batch['labels'])
loss.backward()
optim.step()
train_loss += loss.item() * batch['labels'].size(0)
train_loss /= len(train_dl.dataset)
model.eval()
val_loss = 0.0
val_accuracy = 0.0
with torch.no_grad():
for batch in val_dl:
logits = model(**batch)
loss = loss_fn(logits, batch['labels'])
val_loss += loss.item() * batch['labels'].size(0)
val_accuracy += (logits.argmax(dim=1) == batch['labels']).sum()
val_loss /= len(val_dl.dataset)
val_accuracy /= len(val_dl.dataset)
log_steps = max(1, int(0.2 * epochs))
losses.append((train_loss, val_loss))
if epoch % log_steps == 0 or epoch == epochs - 1:
epoch_duartion = time.time() - epoch_start
print(f'Epoch {epoch+1}/{epochs}, Training Loss: {train_loss:.4f}, Validation Loss: {val_loss:.4f}, Validation Accuracy: {val_accuracy:.4f}. Epoch Duration: {epoch_duartion:.1f} seconds')
train_duration = time.time() - train_start
print(f"Training finished. Took {train_duration:.1f} seconds")
return losses
1
2
torch_losses = train(torch_classifier, train_dl, test_dl, epochs=20)
my_losses = train(my_classifier, train_dl, test_dl, epochs=20)
After training both the models for 20 epochs the accuracy in validation set is around 87%. Classifier using Pytorch Encoder took 22 minutes where as the one we implemented took only 15 minutes in my machine (CPU only training).
Below is the train/validation loss per epoch.
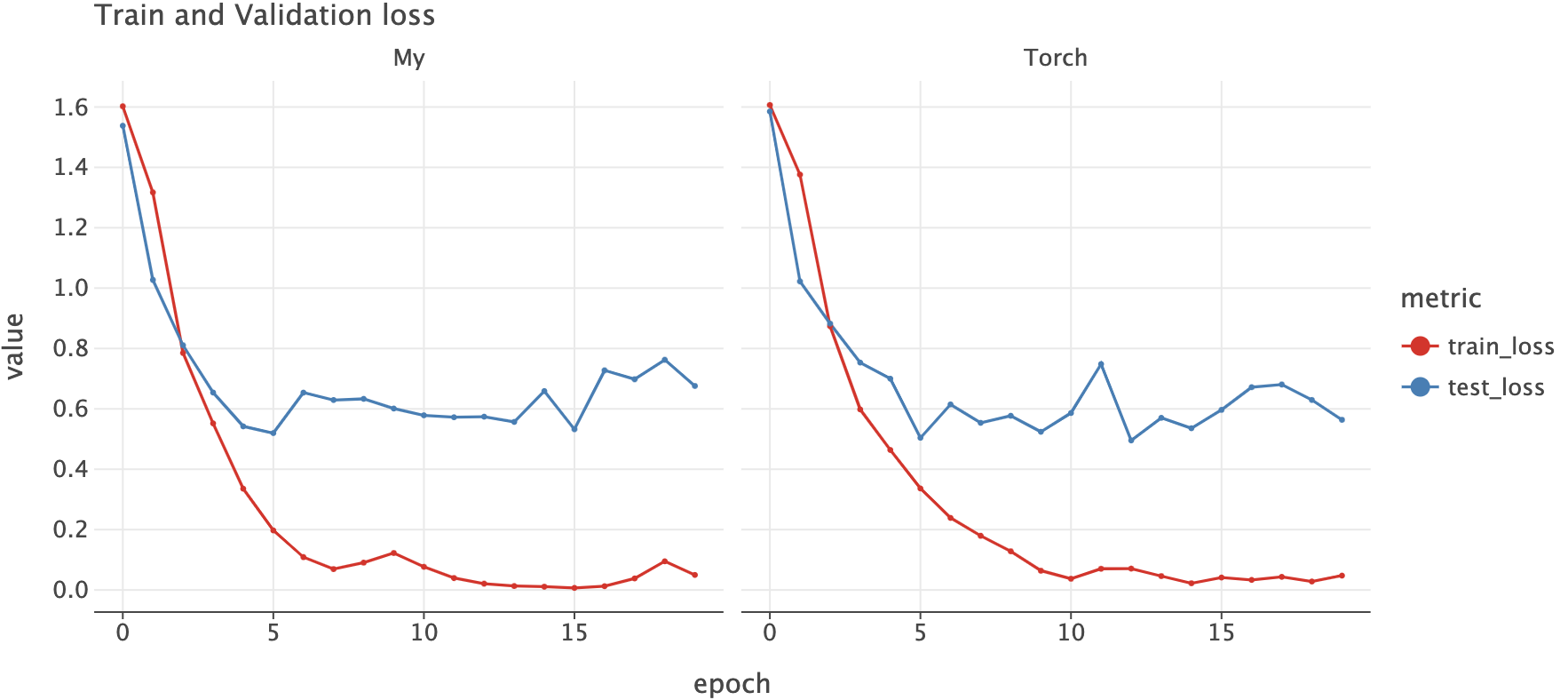
Click to expand visualization code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
def get_losses_as_df(losses_name_pairs: list[tuple[str, tuple[float, float]]]):
dfs = []
for model_name, losses in losses_name_pairs:
df = pd.DataFrame(losses, columns=['train_loss', 'test_loss']).reset_index().rename(columns={"index": "epoch"})
df['model'] = model_name
dfs.append(df)
return pd.concat(dfs)
def plot_losses(loss_df):
df = loss_df.melt(id_vars=['model', 'epoch'], var_name='metric')
return ggplot(df, aes('epoch', 'value', color='metric')) + geom_line() + geom_point(size=1.5) + facet_grid('model') + labs(title="Train and Validation loss")
plot_losses(get_losses_as_df([("My", my_losses), ("Torch", torch_losses)]))
Below is the full classification report per class for both of the models.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
My Classifier
precision recall f1-score support
0 0.88 0.81 0.84 47
1 0.82 0.81 0.82 69
2 0.90 0.96 0.93 81
3 0.89 0.76 0.82 55
4 0.84 0.95 0.89 55
accuracy 0.87 307
macro avg 0.87 0.86 0.86 307
weighted avg 0.87 0.87 0.86 307
Torch Classifier
precision recall f1-score support
0 0.93 0.79 0.85 47
1 0.87 0.87 0.87 69
2 0.92 0.89 0.91 81
3 0.86 0.93 0.89 55
4 0.79 0.87 0.83 55
accuracy 0.87 307
macro avg 0.87 0.87 0.87 307
weighted avg 0.88 0.87 0.87 307
Click to expand evaluation code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
import toolz
def predict(texts, model, bs=32):
output_dfs = []
for batch in toolz.partition_all(bs, texts):
inputs = tokenizer(batch, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad():
class_probs = torch.softmax(model(**inputs), dim=1).numpy()
pred_classes = class_probs.argmax(axis=1)
col_names = [f"class_{i}_prob" for i in range(class_probs.shape[-1])]
df = pd.DataFrame(class_probs, columns=col_names)
df['pred_class'] = pred_classes
df['pred_class_name'] = df['pred_class'].map(class_id_to_class)
output_dfs.append(df)
return pd.concat(output_dfs)
my_preds_df = predict(ds['test']['text'], my_classifier)
my_preds_df['model'] = 'My Model'
my_preds_df['actual_class'] = ds['test']['label']
torch_preds_df = predict(ds['test']['text'], torch_classifier)
torch_preds_df['model'] = 'Torch Model'
torch_preds_df['actual_class'] = ds['test']['label']
from sklearn.metrics import classification_report
print("My Classifier")
print(classification_report(my_preds_df['actual_class'], my_preds_df['pred_class']))
print("Torch Classifier")
print(classification_report(torch_preds_df['actual_class'], torch_preds_df['pred_class']))
Conclusion
We implemented an Encoder network from scratch (kind of) and saw that our implementation and Pytorch’s implementation are quite comparable in terms of model accuracy. Since our implementation is quite simple and does not consider additional cases, it is relatively faster than Pytorch. I hope you enjoyed the post. Let me know if there are any errors.
This article is Part 3 in a 5-Part Understanding Transformers Architecture.




Comments