Objective
- To train a model that predicts the numbers and letters from license plates in Nepali motorbikes
Source code available at https://github.com/jangedoo/LPR
In this short experiment, we’ll train a deep convolutional neural network that classifies digits and characters present in license plates of Nepali motorbikes.
Dataset
This dataset comes from https://github.com/Prasanna1991/LPR and quoting them directly
LPR(License Plate Recognition) dataset contains the cropped image of license plate of private motorbikes in Bagmati zone in Nepal. And thus contains the 12 different classes: ०-९, बा and प.
Here is a picture showing some of the sample data in our dataset.

In total we have 2033 images from all 12 categories. Let’s look at how many samples we have for each category.
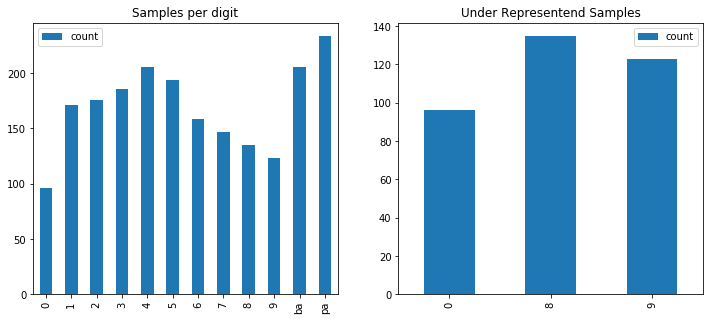
It seems that the digit 0 has the least(96) number of samples whereas digit pa has the most(234). Digits 0, 8 and 9 are comparatively under-represented. We’ll use data augmentation to tackle this issue. A Jupyter notebook containing code for this visualization can be found at https://github.com/jangedoo/LPR/blob/master/Exploratory%20Data%20Analysis.ipynb
Model
Our model will be a fairly straightforward convolutional neural network. Our network consists of 6 convolution blocks, then a GlobalMaxPool2D followed by 2 Dense(fully connected) layers. A Convolution block consists of convolution layer, followed by batch normalization followed by max pooling. We’ll double the number of filters as we add the blocks. We’ll use GlobalMaxPool2D instead of regular Flatten layer to convert 2D data into 1D so that we can feed it to the Dense layers since Dense layers only take 1D inputs. All our layers will use ReLU activation except for the last Dense layer; which will use a softmax.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
from keras.layers import Input, Dense, BatchNormalization, Conv2D, MaxPool2D, GlobalMaxPool2D, Flatten
from keras.models import Model
def conv_block(inp, filters=32, bn=True, pool=True):
_ = Conv2D(filters=filters, kernel_size=3, activation='relu')(inp)
if bn:
_ = BatchNormalization()(_)
if pool:
_ = MaxPool2D()(_)
return _
input_img = Input(shape=(im_height, im_width, 3))
_ = conv_block(input_img, filters=32, bn=False, pool=False)
_ = conv_block(_, filters=32*2)
_ = conv_block(_, filters=32*3)
_ = conv_block(_, filters=32*4)
_ = conv_block(_, filters=32*5)
_ = conv_block(_, filters=32*6)
_ = GlobalMaxPool2D()(_)
_ = Dense(units=128, activation="relu")(_)
_ = Dense(units=12, activation="softmax")(_)
model = Model(inputs=input_img, outputs=_)
model.compile(optimizer='sgd', loss='categorical_crossentropy', metrics=['accuracy'])
Training
To train, we’ll use SGD. You can experiment with other optimizers. As for the training data, we’ll use ImageDataGenerator class provided by Keras to perform data augmentation and also split our data into training and validation set.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
im_width = im_height = 128
batch_size = 32
validation_split = 0.3
datagen = ImageDataGenerator(rescale=1.0/255.0,
validation_split=validation_split,
shear_range=0.2,
zoom_range=0.2,
rotation_range=10,
)
train_gen = datagen.flow_from_directory(images_dir, target_size=(im_height, im_width), batch_size=batch_size, subset="training")
validation_gen = datagen.flow_from_directory(images_dir, target_size=(im_height, im_width), batch_size=batch_size, subset="validation")
train_steps_per_epoch = int(total_images * (1 - validation_split)) // batch_size
validation_steps_per_epoch = int(total_images * validation_split) // batch_size
history = model.fit_generator(train_gen, steps_per_epoch=train_steps_per_epoch, epochs=20,
validation_data=validation_gen, validation_steps=validation_steps_per_epoch)
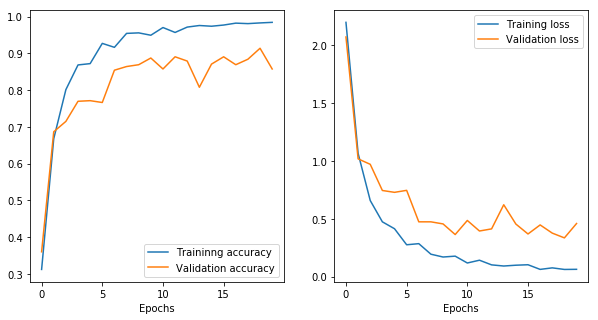
Once trained for 20 epochs, I get something like this below. Training loss and accuracy seem to improve with each epoch but the performance on validation set is fluctuating. There are many reasons for this and is best to experiment with different hyper-parameters and data augmentation strategies.
Prediction
Finally, let’s predict some images in the validation set. Figure below shows the predictions. Orig means true label and Pred means predicted label.

Conclusion
To conclude, we trained a CNN to classify digits and characters present in license plate. We also used data augmentation to generate more variation in our dataset. This is a simple dataset where each characters are already cropped as a separate images. However, a more challenging task would be to automatically locate the license plate in a photo, identify the characters and predict each of them. We’ll visit this problem in future.




Comments