This is the second part of the series: Gender classification. In the first part, we looked at our data-set and downloaded the images from the Internet. In this part we will build a simple convolutional neural network in Keras to classify whether a person in an image is male or female.
Let’s import some required libraries and define helper function to plot the data.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
%matplotlib inline
TRAIN_DIR = "./data/train"
TEST_DIR = "./data/test"
IM_WIDTH = 198
IM_HEIGHT = 198
def plot_images(images, labels):
n_cols = min(5, len(images))
n_rows = len(images) // n_cols
fig = plt.figure(figsize=(8, 8))
for i in range(n_rows * n_cols):
sp = fig.add_subplot(n_rows, n_cols, i+1)
plt.axis("off")
plt.imshow(images[i], cmap=plt.cm.gray)
sp.set_title(labels[i])
plt.show()
Now we can build a model. We built a similar model in the post where we classified cat vs dog, so I’ll not go in detail. The model consists of 5 convolution blocks of conv2d->relu->batch norm->max pool. However, note that in the last convolution block, I’m using GlobalAvgPool2D layer. In our case, the batch normalization layer above it returns a tensor of shape 8,8,128. Global average pooling will average the value of 8,8 slice (or whatever spatial dimension) and returns a vector that has same dimension as the number of channels in its inputs (128 in our case). Because of this, we don’t need to use Flatten layer as we did in cat vs dog experiment.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
from keras.layers import Input, Dense, Flatten, Conv2D, MaxPool2D, BatchNormalization, Activation, GlobalAvgPool2D
from keras.models import Model
img_input = Input(shape=(IM_HEIGHT, IM_WIDTH, 3))
_ = Conv2D(filters=32, kernel_size=3)(img_input)
_ = Activation("relu")(_)
_ = BatchNormalization()(_)
_ = MaxPool2D()(_)
_ = Conv2D(filters=64, kernel_size=3)(_)
_ = Activation("relu")(_)
_ = BatchNormalization()(_)
_ = MaxPool2D()(_)
_ = Conv2D(filters=64, kernel_size=3)(_)
_ = Activation("relu")(_)
_ = BatchNormalization()(_)
_ = MaxPool2D()(_)
_ = Conv2D(filters=128, kernel_size=3)(_)
_ = Activation("relu")(_)
_ = BatchNormalization()(_)
_ = MaxPool2D()(_)
_ = Conv2D(filters=128, kernel_size=3)(_)
_ = Activation("relu")(_)
_ = BatchNormalization()(_)
_ = GlobalAvgPool2D()(_)
_ = Dense(128)(_)
_ = Activation("relu")(_)
_ = BatchNormalization()(_)
_ = Dense(1)(_)
_ = Activation("sigmoid")(_)
model = Model(inputs=img_input, outputs=_)
model.compile(optimizer="adam", loss="binary_crossentropy", metrics=["accuracy"])
model.summary()
We’ll use ImageDataGenerator class provided by Keras library. It provides an easy way to generate batches of images with data augmentation. For our purpose, we’ll define two data generators- one for training and one for testing.
For training data generator we’ll tell it to perform the following:
- normalize the pixel values so that they lie between 0 and 1 instead of 0 and 255
- randomly rotate images from 0 to 20 degrees
- randomly flip the image horizontally
For testing data generator we’ll only tell it to normalize the pixel values.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
from keras.preprocessing.image import ImageDataGenerator
train_data_gen = ImageDataGenerator(rescale=1./255,
rotation_range=20,
horizontal_flip=True
)
test_data_gen = ImageDataGenerator(rescale=1./255)
batch_size = 32
train_gen = train_data_gen.flow_from_directory(TRAIN_DIR,
target_size=(IM_WIDTH, IM_HEIGHT),
class_mode="binary",
batch_size=batch_size)
test_gen = test_data_gen.flow_from_directory(TEST_DIR,
target_size=(IM_WIDTH, IM_HEIGHT),
class_mode="binary",
batch_size=batch_size)
# now we can train the model
history = model.fit_generator(train_gen, steps_per_epoch=len(train_gen.filenames)//batch_size, epochs=16)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
Epoch 1/16
302/302 [==============================] - 132s - loss: 0.4542 - acc: 0.7822
Epoch 2/16
302/302 [==============================] - 132s - loss: 0.4290 - acc: 0.7912
Epoch 3/16
302/302 [==============================] - 132s - loss: 0.4080 - acc: 0.8043
Epoch 4/16
302/302 [==============================] - 132s - loss: 0.3835 - acc: 0.8207
Epoch 5/16
302/302 [==============================] - 132s - loss: 0.3527 - acc: 0.8375
Epoch 6/16
302/302 [==============================] - 132s - loss: 0.3312 - acc: 0.8508
Epoch 7/16
302/302 [==============================] - 137s - loss: 0.3112 - acc: 0.8557
Epoch 8/16
302/302 [==============================] - 140s - loss: 0.2967 - acc: 0.8670
Epoch 9/16
302/302 [==============================] - 136s - loss: 0.2784 - acc: 0.8765
Epoch 10/16
302/302 [==============================] - 140s - loss: 0.2687 - acc: 0.8819
Epoch 11/16
302/302 [==============================] - 135s - loss: 0.2517 - acc: 0.8881
Epoch 12/16
302/302 [==============================] - 135s - loss: 0.2460 - acc: 0.8903
Epoch 13/16
302/302 [==============================] - 133s - loss: 0.2422 - acc: 0.8955
Epoch 14/16
302/302 [==============================] - 135s - loss: 0.2301 - acc: 0.9003
Epoch 15/16
302/302 [==============================] - 134s - loss: 0.2191 - acc: 0.9036
Epoch 16/16
302/302 [==============================] - 135s - loss: 0.2114 - acc: 0.9117
I already trained the model for 2 epochs before I ran it again for 16 more. So your output will be different. Anyways, we achieved an accuracy of 91%. Let’s evaluate our model in the testing set.
1
2
model.evaluate_generator(test_gen, steps=len(test_gen.filenames)//batch_size)
> [0.25906037643205287, 0.8839631782945736]
The output of evaluation returns a list of numbers. The first number is the loss and second is accuracy. We managed to get 88% accuracy in testing set! Our model is pretty small with just 296,577 parameters and we were able to achieve a decent accuracy.
Finally, let’s visualize some of the predictions.
1
2
3
4
5
6
7
8
9
10
# predict for one batch of test images
imgs, y_true = next(test_gen)
predictions = model.predict(imgs, batch_size=imgs.shape[0])
# how do I know if male is 0 or 1? ImageDataGenerator has a property class_indices
# try printing test_gen.class_indices
# since sigmoid produces value between 0 and 1, we create a threshold and say
# any value > 0.5 is a male otherwise it is female
predictions_str = np.where(predictions.flatten() > 0.5, "male", "female")
plot_images(imgs, predictions_str)
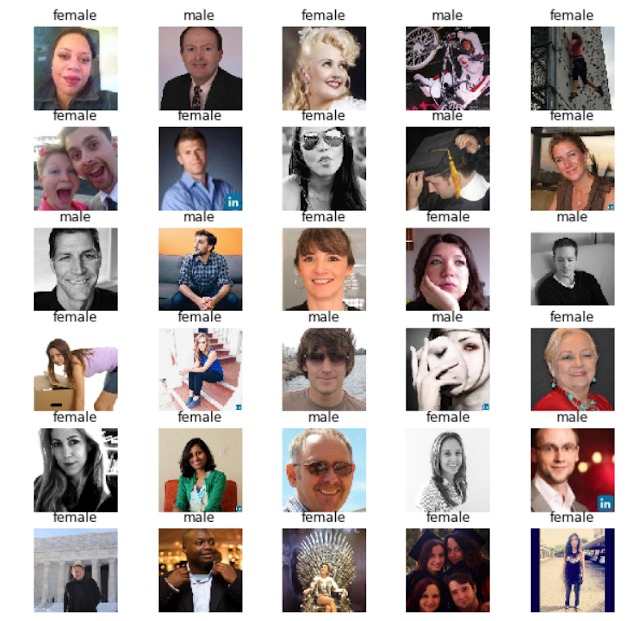
In next part of this series we’ll use this model to predict gender of people in real-time.




Comments