This article is Part 4 in a 5-Part Understanding Transformers Architecture.
Introduction
In this post we’ll implement the Transformer’s Decoder layer from scratch. This was introduced in a paper called Attention Is All You Need. This layer is typically used to build “Decoder only” models such as ChatGPT, LLama etc. Of course we can combine the Decoder with Encoder as proposed in the paper but in this post, we’ll use the Decoder layers to build a Decoder-only model similar to GPT.
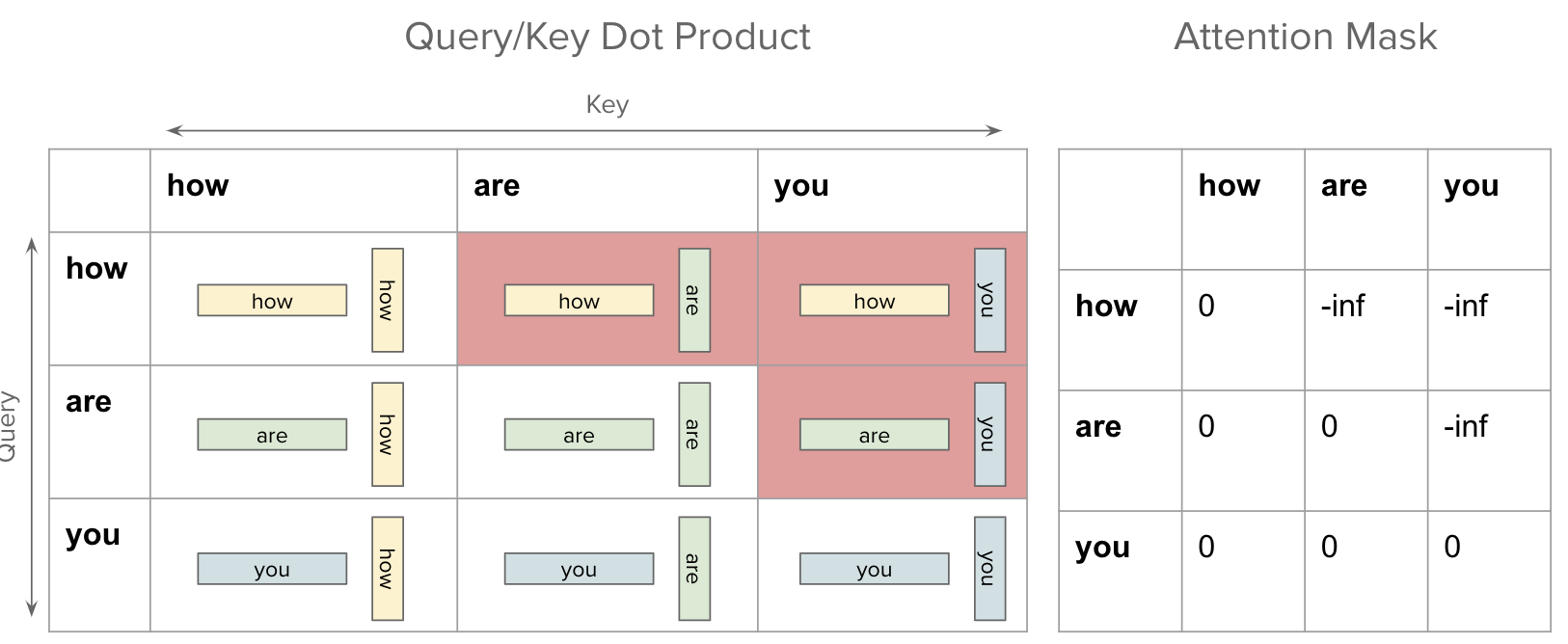
Decoder layer is very similar to the Encoder layer. Only difference is how masking is used. As explained in previous post, we’ll use causal mask when calculating the attention. To be more precise, Decoders are used to build model which generate the next token in sequence. During training, the model can technically “see” future tokens as well but to prevent this data leakage, we introduce causal mask so that attention is calculated using the tokens observed so far.
The image below shows how the future tokens are “excluded” by setting their mask value to negative infinity when calculating attention weights in the MultiHeadAttention layer. Please refer to previous post where I cover this in more detail.
Implementation
Implementing it is quite straight forward. Let’s import few libraries and implement two classes DecoderLayer and Decoder. Decoder class just encapsulates N number of DecoderLayers.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
# pip install -q lightning datasets
import numpy as np
import pandas as pd
import torch
import lightning as L
from copy import deepcopy
class DecoderLayer(torch.nn.Module):
def __init__(
self,
embed_dim: int,
n_heads: int,
dim_feedforward: int = 512,
dropout: float = 0.1,
):
super().__init__()
self.mha = torch.nn.MultiheadAttention(
embed_dim=embed_dim, num_heads=n_heads, dropout=0.1, batch_first=True
)
self.norm1 = torch.nn.LayerNorm(normalized_shape=embed_dim)
self.norm2 = torch.nn.LayerNorm(normalized_shape=embed_dim)
self.dropout1 = torch.nn.Dropout(p=dropout)
self.dropout2 = torch.nn.Dropout(p=dropout)
self.ff_block = torch.nn.Sequential(
torch.nn.Linear(in_features=embed_dim, out_features=dim_feedforward),
torch.nn.ReLU(),
torch.nn.Linear(in_features=dim_feedforward, out_features=embed_dim),
)
def forward(self, x: torch.Tensor, key_padding_mask=None, attn_mask=None):
attn_output, attn_weights = self.mha(
x, x, x, attn_mask=attn_mask, key_padding_mask=key_padding_mask
)
x = self.norm1(x + self.dropout1(attn_output))
projection = self.ff_block(x)
x = self.norm2(x + self.dropout2(projection))
return x
class Decoder(torch.nn.Module):
def __init__(self, decoder_layer, num_layers: int):
super().__init__()
layers = []
for _ in range(num_layers):
layers.append(deepcopy(decoder_layer))
self.layers = torch.nn.ModuleList(layers)
def forward(self, x, key_padding_mask=None, attn_mask=None):
for layer in self.layers:
x = layer(x, key_padding_mask=key_padding_mask, attn_mask=attn_mask)
return x
Now that we have the building blocks. Let’s implement a model similar to GPT. We need new parameters like number of decoder layers, embedding dimension, number of heads etc. which we will accept in the __init__ function. In the end, the model will return probabilities of next token.
Click to expand Positional Embedding code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import math
class PositionalEncoding(torch.nn.Module):
# source: https://uvadlc-notebooks.readthedocs.io/en/latest/tutorial_notebooks/tutorial6/Transformers_and_MHAttention.html#Positional-encoding
def __init__(self, embed_dim, max_len=256):
super().__init__()
# create a matrix of [seq_len, hidden_dim] representing positional encoding for each token in sequence
pe = torch.zeros(max_len, embed_dim)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # (max_len, 1)
div_term = torch.exp(torch.arange(0, embed_dim, 2).float() * (-math.log(10000.0) / embed_dim))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe, persistent=False)
def forward(self, x):
x = x + self.pe[:, :x.size(1)]
return x
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
class TinyGPT(torch.nn.Module):
def __init__(
self,
num_layers: int,
vocab_size: int,
embed_dim: int,
max_len: int,
n_heads: int,
dim_feedforward: int,
pad_token_idx: int,
dropout: float = 0.1,
):
super().__init__()
self.embedding = torch.nn.Embedding(
num_embeddings=vocab_size, embedding_dim=embed_dim, padding_idx=pad_token_idx
)
self.positional_encoding = PositionalEncoding(embed_dim=embed_dim, max_len=max_len)
self.decoders = Decoder(
decoder_layer=DecoderLayer(
embed_dim=embed_dim,
n_heads=n_heads,
dim_feedforward=dim_feedforward,
dropout=dropout,
),
num_layers=num_layers,
)
self.lm_head = torch.nn.Linear(in_features=embed_dim, out_features=vocab_size)
def forward(self, input_ids, key_padding_mask=None):
bs, seq_len = input_ids.size()
embeddings = self.get_embeddings(input_ids)
# generate a causal mask
attn_mask = torch.nn.Transformer.generate_square_subsequent_mask(sz=seq_len, device=input_ids.device)
embeddings = self.decoders(embeddings, key_padding_mask=key_padding_mask, attn_mask=attn_mask)
logits = self.lm_head(embeddings)
return logits
def get_embeddings(self, input_ids):
return self.positional_encoding(self.embedding(input_ids))
def get_model_param_count(self):
return sum(t.numel() for t in self.parameters())
def generate(self, tokenizer, initial_text=None, max_len: int=20):
device = next(self.parameters()).device
input_ids = [tokenizer.cls_token_id]
if initial_text:
# tokenizer add SEP token at the end, do not include that one
input_ids = tokenizer(initial_text)['input_ids'][:-1] # type: ignore
while len(input_ids) < max_len:
logits = self(input_ids=torch.LongTensor(input_ids).unsqueeze(0).to(device))
# take the logits of the last token and use a temperature of 0.1
logits = logits[0][-1] / 0.1
# greedy sampling. take the token with max "probability"
next_token_id = logits.argmax(dim=-1).item()
input_ids.append(next_token_id)
if next_token_id == tokenizer.sep_token_id:
break
return tokenizer.decode(input_ids)
The most important part to consider is in the forward method, we generated a causal mask and passed that mask as attn_mask argument to the decoders layer.
1
attn_mask = torch.nn.Transformer.generate_square_subsequent_mask(sz=seq_len, device=input_ids.device)
The generate takes the logit produced by last token in the input and then chooses the next token as the token with highest value (also called greedy decoding). We’ll discuss about sampling in future posts.
Now let’s train our model. For training, let’s download a dataset from HuggingFace Hub and pre-process it.
1
2
3
4
5
6
7
8
9
10
11
12
import datasets
from transformers import AutoTokenizer
# can choose other tokenizers as well
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
# let's limit the max number of tokens in a sequence to be 128.
# longer sequences will be truncated
tokenizer.model_max_length = 128
news_ds = datasets.load_dataset("fancyzhx/ag_news", split="train")
def tokenize(batch):
return tokenizer(batch['text'], truncation=True)
news_ds = news_ds.map(tokenize, batched=True)
We now have dataset and also extracted token ids. Let’s define a DataCollator and create train and test data loaders.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
class DataCollatorForLM:
def __init__(self, pad_token_idx: int):
self.pad_token_idx = pad_token_idx
def __call__(self, batch):
input_ids = []
# collect the input_ids as torch Tensor
for row in batch:
input_ids.append(torch.LongTensor(row['input_ids']))
# pad the input_ids so that all of them have same shape
input_ids = torch.nn.utils.rnn.pad_sequence(input_ids, batch_first=True, padding_value=self.pad_token_idx)
# any input_ids that is same as pad_token_idx will be considered as key padding mask
# for a mask, value of True means it will not take part in attention
key_padding_mask = input_ids == self.pad_token_idx
# labels will be same as the input_ids
# we will shift the labels when calculating the loss
labels = input_ids.clone()
# we also set the token_id of padded tokens to -100 so that we can ignore these
# when calculating cross entropy loss because we do not care what the model predicts
# for these padded tokens
labels[labels == self.pad_token_idx] = -100
return {"input_ids": input_ids, "key_padding_mask": key_padding_mask, "labels": labels}
This collator is just collecting the input ids as tensor after padding. As mentioned in the comments, it also “creates” labels which is same as input ids. Later when we compute the loss, we’ll shift the labels so that the labels will be the next token in the sequence.
1
2
3
4
5
6
from torch.utils.data import DataLoader
news_ds = news_ds.train_test_split(test_size=0.2)
bs = 128
collate_fn = DataCollatorForLM(pad_token_idx=tokenizer.pad_token_id)
train_dl = DataLoader(news_ds['train'], batch_size=bs, shuffle=True, collate_fn=collate_fn)
test_dl = DataLoader(news_ds['test'], batch_size=bs, shuffle=False, collate_fn=collate_fn)
I’ve used Pytorch Lightning library to train. So let’s create a wrapper class using LightningModule. This is done so that we can use its Trainer class and avoid writing our own training loop. This class has a method compute_loss which shifts the labels and calculates the loss using cross_entropy loss function.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
class LitTinyGPT(L.LightningModule):
def __init__(self, gpt: TinyGPT):
super().__init__()
self.gpt = gpt
def compute_loss(self, batch):
input_ids = batch["input_ids"]
key_padding_mask = batch["key_padding_mask"]
labels = batch["labels"]
logits = self.gpt(input_ids=input_ids, key_padding_mask=key_padding_mask)
# flatten the labels
shift_labels = labels[..., 1:].contiguous().view(-1) # 1D array with total elements = bs * (seq_len - 1)
# shift logits so that we discard the probabilties for the last one
# since final token does not have next token to predict
shift_logits = logits[..., :-1, :].contiguous()
shift_logits = shift_logits.view(-1, shift_logits.size(-1)) # 2D array
# we ignore the predictions for labels which have value of -100 (as specified in the data collator)
loss = torch.nn.functional.cross_entropy(
shift_logits, target=shift_labels, ignore_index=-100
)
return loss
def training_step(self, batch, batch_idx):
loss = self.compute_loss(batch=batch)
self.log("train_loss", loss, prog_bar=True, on_epoch=True, on_step=True)
return loss
def validation_step(self, batch, batch_idx):
loss = self.compute_loss(batch=batch)
self.log_dict({"val_loss": loss, "perplexity": torch.exp(loss)}, on_epoch=True, on_step=True)
def configure_optimizers(self):
optim = torch.optim.Adam(params=self.parameters(), lr=1e-3)
return optim
Ok, we are almost to the end. Now we just need to create our “tiny GPT” model.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 4 decoder layers
num_layers = 4
vocab_size = tokenizer.vocab_size
# embedding size of 512
embed_dim = 512
# 8 heads on MHA
n_heads = 8
dim_feedforward = 2048
# max_len is needed by PositionalEmbedding
max_len = tokenizer.model_max_length
gpt = TinyGPT(
num_layers=num_layers,
vocab_size=vocab_size,
max_len=max_len,
embed_dim=embed_dim,
n_heads=n_heads,
dim_feedforward=dim_feedforward,
pad_token_idx=tokenizer.pad_token_id,
dropout=0.1,
)
lit_gpt = LitTinyGPT(gpt=gpt)
print(f"Total model parameters = {gpt.get_model_param_count():,}")
Using the above configuration, the model has 43 million parameters. The smallest GPT-2 model has 124 million parameters.
Finally we can train our model. I’ve also created a callback so that it generates 3 texts after every epoch to see how sensible the generated texts look like after each epoch.
Click to expand Callback code
1
2
3
4
5
6
7
8
9
10
11
12
from lightning import LightningModule, Trainer
class MyCallaback(L.Callback):
def generate_texts(self, pl_module: LitTinyGPT):
pl_module.print(pl_module.gpt.generate(tokenizer=tokenizer, initial_text=None, max_len=30))
pl_module.print()
pl_module.print(pl_module.gpt.generate(tokenizer=tokenizer, initial_text="france starts", max_len=30))
pl_module.print()
pl_module.print(pl_module.gpt.generate(tokenizer=tokenizer, initial_text="vw considers opening", max_len=30))
pl_module.print("==============")
def on_train_epoch_end(self, trainer: Trainer, pl_module: LightningModule) -> None:
self.generate_texts(pl_module=pl_module)
1
2
3
num_epochs = 5
trainer = L.Trainer(fast_dev_run=False, max_epochs=num_epochs, max_steps=-1, log_every_n_steps=20, callbacks=[MyCallaback()])
trainer.fit(lit_gpt, train_dataloaders=train_dl, val_dataloaders=test_dl)
I’ve trained it for 5 epochs in Google Colab. It used about 13.6 GB of VRAM while training and took about 14 minutes per epoch.
Let’s look at the texts generated over the epochs. The first kind of “text” is without any initial text, so the model basically is free to generate whatever it wants. Looking at the logs it always starts the sentence with the word “us”.
1
2
3
4
5
1. [CLS] us stocks rise on oil prices, oil prices rise new york ( reuters ) - u. s. stocks were higher on thursday as a disappointing consumer
2. [CLS] us, china, china, china and china, china and china are the world # 39 ; s booming economy, china and china are booming china
3. [CLS] us, iraqi forces kill 22 in iraq, us and iraqi forces killed 22 insurgents killed 22 insurgents in the iraqi city of falluja, the
4. [CLS] us airways pilots union at us airways group inc., the no. 2 us airways group inc., said thursday it would cut wages and benefits
5. [CLS] us, eu leaders sign new eu trade pact the european union and the eu agreed to sign a new eu trade agreement on friday to end a row
The second kind of text was given an initial text = france starts.
1
2
3
4
5
1. [CLS] france starts new anti - spam law ( ap ) ap - french lawmakers are expected to announce a new anti - spam law that could
2. [CLS] france starts new nuclear missile shield ( ap ) ap - france will launch a new weapon against the international atomic energy agency next year, a new weapon
3. [CLS] france starts new hostages in iraq the french government is investigating a french hostage crisis in iraq, france and the french government said on thursday. [SEP]
4. [CLS] france starts new hostages in iraq two french hostages have been freed in iraq, the french government said on wednesday. the two french hostages in iraq,
5. [CLS] france starts new - generation of portable music player ( reuters ) reuters - france's new portable music player \ has started a new digital music player
The third one was given an initial text = vw considers.
1
2
3
4
5
1. [CLS] vw considers opening day of the world # 39 ; s largest airline, said it would cut its work force in its pilots and the united states
2. [CLS] vw considers opening of its debt, the german finance ministers of the european union # 39 ; s biggest lender, said it would consider a
3. [CLS] vw considers opening - up to - ups plants new york ( reuters ) - volkswagen ag has warned on tuesday it would consider a formal request to
4. [CLS] vw considers opening of the frankfurt volkswagen ag has warned that the company will not charge for the first time in its initial public offering, the company
5. [CLS] vw considers opening offer for unions frankfurt ( reuters ) reuters - volkswagen ag's \ deutsche telekom said on thursday it was considering a
Let’s look at some texts generated after the model was trained. The bold text is the “initial text”.
- [CLS] microsoft and nvidia cross - licensing deal to provide content management software for software, microsoft and yahoo! have signed a cross - licensing agreement to develop a common language that will help companies manage their work. [SEP]
- [CLS] nvidia announces geforce 6 gpu ibm has announced a new gp versions of its geforce 6 processor, which allows users to manage the gpu and the gpu. [SEP]
- [CLS] a new trade agreement for iran nuclear program the united nations is considering making a new round of talks to end a dispute over iran # 39 ; s nuclear program, the bbc said on friday. [SEP]
The generated texts kind of make sense but no one is getting fooled by this. Few reasons for this
- Small model size (only 43 million parameters)
- Small dataset (focused on news only). We also didn’t do any data cleaning.
- Not trained enough. Perhaps we could have trained it for more epochs. Even if we did, the quality of generated texts won’t be usable for any purpose :)
- Greedy sampling when generating. We just selected the next token which has the highest probability. This does not always give us good results. This is true for bigger models as well. In the next post, I’ll cover sampling strategies. You can also refer to this post for Hugging Face to get an idea of different strategies.
Conclusion
We implemented Transformer Decoder layer and trained a Decoder only model similar to GPT. Only thing that is different to the Encoder is the use of Causal Mask, otherwise the encoder and decoder are pretty much the same. I hope you found this post useful. Please let me know if there are any errors.
This article is Part 4 in a 5-Part Understanding Transformers Architecture.




Comments