This article is Part 5 in a 5-Part Understanding Transformers Architecture.
Introduction
Generative models such as GPT generate one token at a time. How we choose the next token plays a very important role in the generated text. There are a few approaches to do this. In this post we’ll cover Greedy sampling, Top-P sampling and Top-K sampling. We’ll also look at how Temperature parameter affects the overall generation process.
Setup
I will demonstrate the concepts along with the code so that you can also follow along. First, let’s import few libraries.
1
2
3
4
5
import numpy as np
import pandas as pd
import torch
from lets_plot import *
LetsPlot.setup_html()
Next we need a model. For this, I’ve used a model I trained as shown in Transformer Decoder post but you can use any model from HuggingFace Hub.
1
2
3
4
5
from transformers import AutoTokenizer
# I used this tokenizer to train the model I trained earlier so I'll use this one
# but feel free to switch to any tokenizer
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
gpt = ... # load a model from HuggingFace Hub. I loaded my model from the disk
Before we dive in, let’s recap how we generate texts.
or Max Length reached} IsEOS -- yes --> Stop IsEOS -- no --> NextTokenId2[Next Token Id] NextTokenId2 -- append --> InputIds style NextTokenId fill:#f9f
Below is a basic implementation of generate function which generates text using the model. This function implements ‘Greedy sampling’. After reading this post you can implement other approaches as well.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
def generate(gpt, tokenizer, initial_text=None, max_len: int=20, temperature: float=1.0):
gpt.eval()
input_ids = [tokenizer.cls_token_id]
if initial_text:
# tokenizer add SEP token at the end, do not include that one
input_ids = tokenizer(initial_text)['input_ids'][:-1] # type: ignore
# you can also check only for newly generated tokens
while len(input_ids) < max_len:
with torch.no_grad():
logits = gpt(input_ids=torch.LongTensor(input_ids).unsqueeze(0)[0]
# take the logits of the last token and scale by temperature
logits = logits[-1] / temperature
# greedy sampling. take the token with max "probability"
# this is where we can implement different sampling strategies
next_token_id = logits.argmax(dim=-1).item()
input_ids.append(next_token_id)
# I've trained the model to use `sep_token_id` as an indicator for End of Sentence token.
# depending on the tokenizer and the model you might have to adjust this.
if next_token_id == tokenizer.sep_token_id:
break
return tokenizer.decode(input_ids)
Ok, now that we know how we generate texts, let’s explore different strategies.
Temperature
First let’s discuss about temperature. You might have already seen this parameter when using APIs for LLMs. The value for this parameter is typically constrained between 0 to 1. Higher temperature means the model gets more creative and is useful when you are generating stories. Lower values can be used to force the model to be more rigid. For example, if you want the model to extract all named entities in the input, you might want to lower the temperature to say around 0.1 or even lower than that.
One thing to note is that temperature parameter is used to scale the logits. So if we are using Greedy sampling i.e. choosing the token with highest logit value, then whatever value we use for temperature will not affect the result. The relative order of logits after scaling won’t change at all.
But this plays an important role when we actually sample i.e. randomly choose a token based on its probability. We convert the logits to probabilities (either raw logits or scaled by temperature) using softmax function, the probability will change depending on the temperature.
Let me give a concrete example. My prompt is microsoft to pay 3.5 billion to settle and I’m asking the model to predict the next token.
The model returns logits or un-normalized scores for 30,522 tokens because that is the vocabulary size of the model. Below, I’ve only selected top 5 tokens (Top-K sampling) based on their logit values and then plotted the data.
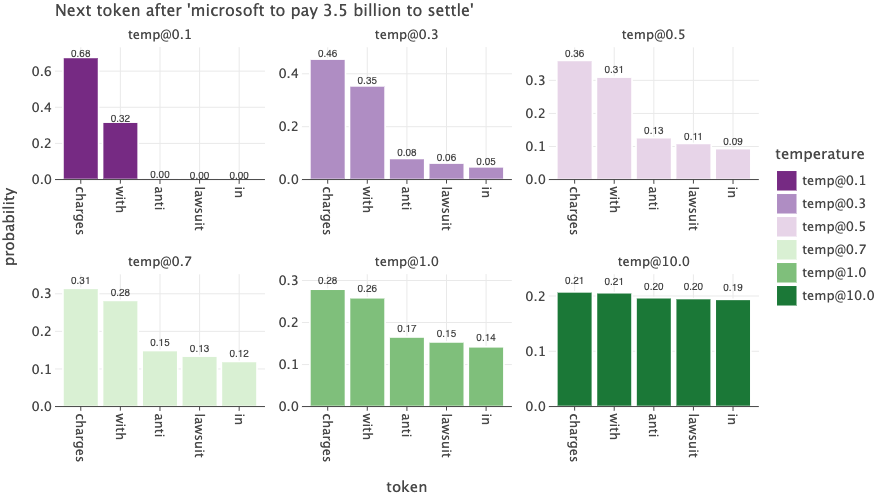
Let’s first focus on the plot where temperature is 1.0 (temp@1) i.e. the logits are not changed because we are just dividing by 1. This will be our baseline to compare.
The token charges has a probability of 0.29, and the word with has probability of 0.26 and so on. This means, if we were to sample from this probability distribution, we have 28% chance of choosing the word charges as next token, 17% chance of selecting the word anti and 14% chance of selecting the word in.
Now let’s switch to the case when we have the lowest temperature (temp@0.1). Here we see the word charges has 68% chance of being the next token and the word with has 32%. The remaining 3 words have no chance at all. So basically we are “magnifying” the probability of tokens with slightly higher logits. This is what limits the “creativity” of the model by limiting the possible choices of tokens because many of them will have very low probability. This also means, that for tasks where such creativity is not needed, such as entity extraction, extractive question answering etc. lower temperature is more appropriate.
If we go a bit extreme and set the temperature to 10, we now see that the probabilities of all tokens are almost the same. If we were to sample from this distribution, all tokens have almost the same chance of being selected as next token. This also basically nullifies the “work” that the model has done and is almost equivalent to sampling from a uniform distribution. We could bascailly randomly select a token from the vocabulary instead of using a model! This is why almost all LLM apis limit the range of temperature between 0 and 1.
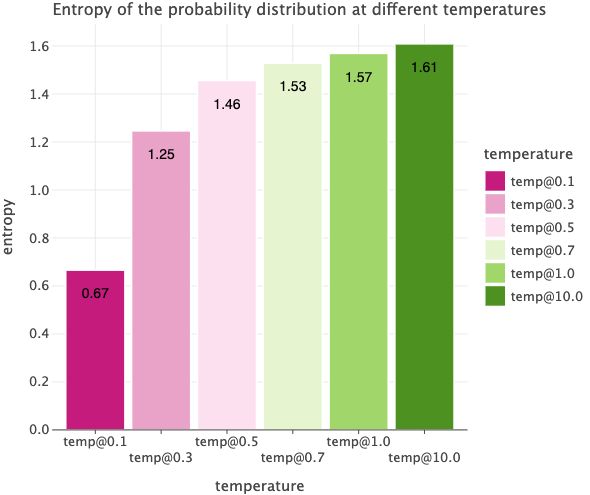
We can also calculate the entropy of the probability distribution from each temperature we used. As we increase the temperature, the entropy increases indicating more uncertainty. E.g. when temperature is 0.1, we only had two tokens with non-zero probability values so we are a bit more confident in which token will come next compared to the case when temperature is 10. In that case, all 5 tokens had almost the same probability so we are less certain about which token will be selected next.
The code to generate the plots above is down below if you want to try it for yourself.
Click to expand code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
def get_logits(initial_text=None):
gpt.eval()
input_ids = [tokenizer.cls_token_id]
if initial_text:
# tokenizer add SEP token at the end, do not include that one
input_ids = tokenizer(initial_text)['input_ids'][:-1] # type: ignore
with torch.no_grad():
logits = gpt(input_ids=torch.LongTensor(input_ids).unsqueeze(0))[0]
# get logits of last token
logits = logits[-1]
return logits
initial_text = "microsoft to pay 3.5 billion to settle"
logits = get_logits(initial_text=initial_text)
values, indices = logits.topk(5)
tokens = tokenizer.convert_ids_to_tokens(indices)
df = pd.DataFrame({"token": tokens, "token_id": indices, "logit": values})
prob_columns = []
for temp in [0.1, 0.3, 0.5, 0.7, 1.0, 10.0]:
prob_column = f'temp@{temp}'
df[prob_column] = torch.softmax(values / temp, dim=-1)
prob_columns.append(prob_column)
bunch = GGBunch()
bunch.add_plot(
(
ggplot(df.melt(id_vars='token', value_vars=prob_columns, var_name='temperature', value_name='prob'), aes('token', 'prob', label='prob'))
+ geom_bar(aes(fill='temperature'), stat='identity')
+ scale_fill_brewer(type='div', palette=2)
+ geom_text(label_format=".2f", nudge_y=0.02, size=5)
+ labs(title=f"Next token after '{initial_text}'", y='probability')
+ facet_wrap('temperature', scales='free', ncol=3)
), 0, 0, 900, 500) # type: ignore
import scipy.stats
bunch.add_plot(
(
ggplot(pd.DataFrame({"entropy": scipy.stats.entropy(df[prob_columns], axis=0), "temperature": prob_columns}), aes('temperature', 'entropy', label='entropy'))
+ geom_bar(aes(fill='temperature'), stat='identity')
+ scale_fill_brewer(type='div', palette=1)
+ geom_text(label_format=".2f", nudge_y=-0.1, color="black")
+ labs(title="Entropy of the probability distribution at different temperatures")
), 900, 0, 600, 500) # type: ignore
bunch
Top K Sampling
Top-K sampling is a very simple approach and yields pretty good results. Basically the idea is that we sort the logits in descending order and take the top K logits. Then using these top K logits, we calculate the probability distribution as shown in the code below.
1
2
top_logits, top_indices = torch.topk(logits, k=5)
top_probs = torch.softmax(top_logits, dim=-1)
Then we sample the next token using the top_probs probability distribution.
But how does this change the results? Let’s look at the probability distribution of Top-5 tokens. The red bar indicates the probabilites of the tokens calculated from top 5 logits and the blue bar indicates the probabilities of same tokens but calculate using the entire logits.
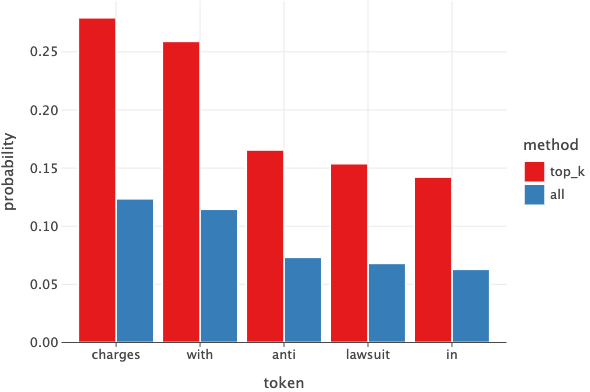
We see dramatic difference in the probability values. For example, the word charges has about 28% chance of being selected using Top-P method vs only about 12% chance when considering all logits.
How I interpret this is that instead of “distributing” the probability values for entire vocabulary (~30K in this case), where most of the tokens will be irrelevant anyways, we only “distribute” the probabilities to the top-K relevant ones.
Click to expand code to generate plot above
1
2
3
4
5
6
7
8
9
10
11
12
13
top_logits, top_indices = torch.topk(logits, k=5)
top_probs = torch.softmax(top_logits, dim=-1)
# to compare let's calculate probabilities using entire logit
probs = torch.softmax(logits, dim=-1)[top_indices]
df = pd.DataFrame({
"token": tokenizer.convert_ids_to_tokens(top_indices),
"top_k": top_probs,
"all": probs,
}).melt(id_vars='token', var_name='method', value_name='probability')
(
ggplot(df, aes('token', 'probability'))
+ geom_bar(aes(fill='method'), stat='identity', position='dodge')
)
Top P Sampling
Top-P sampling is another approach similar to Top-K but instead of a hard threshold like top 5 or top 10 tokens, we select dynamic number tokens based on the cumulative probability p. Let’s look at an example to be concrete. Let’s say we have p = 0.61.
The right plot below shows the probabilites of top 15 tokens based on their probabilities and the left one shows cumulative probabilities of these tokens.
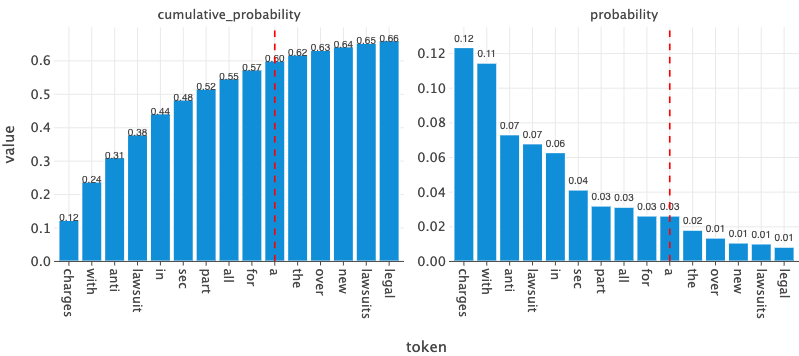
Since our threshold or p = 0.61, we select the tokens whose cumulative probability is less than or equal to p. In this case, we select the tokens starting from charges to a i.e 10 tokens were selected.
Now based on the logits of only these tokens, we calculate the probabilites.
The image below compares the probabilities of the tokens computed using the entire logits or using Top-P logits. Like Top-K method, we’ve amplified the probabilities of the relevant tokens. For example, the word charges has 20% chance of being next token using Top-P method compared to 12% using all logits. Note that the same token had 28% chance when using Top-k=5.
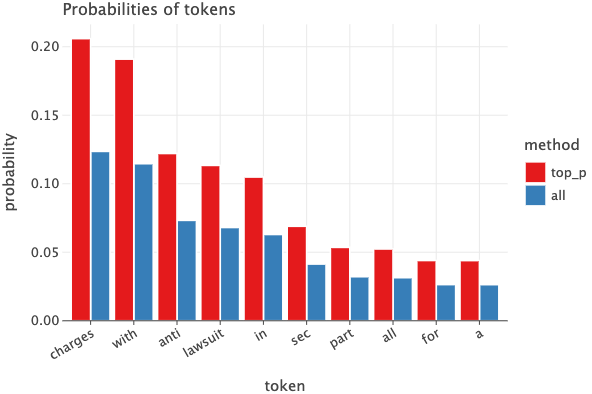
The code below should make things clear.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
top_p = 0.61
# sort the logits
sorted_logits, sorted_indices = torch.sort(logits, descending=True)
sorted_probs = torch.softmax(sorted_logits, dim=-1)
# compute cumulative probabilities
cum_probs = torch.cumsum(sorted_probs, dim=-1)
# create a mask indicating if cumulative probability is less than the top_p
valid_mask = cum_probs <= top_p
# find the cutoff index
cutoff_index = torch.nonzero(valid_mask, as_tuple=False).max().item()
# get the token indices and their probabilities upto and including the cutoff index
valid_indices = sorted_indices[:cutoff_index+1]
# calculate the probabilities again using subset of logits
valid_probs = torch.softmax(sorted_logits[:cutoff_index+1], dim=-1)
By the way, both Top-K and Top-P approach can be used together.
Implementation
Below is the implementation for 3 approaches: Greedy, TopK and TopP.
Greedy
1
2
3
class GreedySampling:
def next_token(self, logits):
return logits.argmax(dim=-1).item()
TopK
1
2
3
4
5
6
7
8
9
class TopKSampling:
def __init__(self, k: int):
self.k = k
def next_token(self, logits):
values, indices = torch.topk(logits, self.k)
probs = torch.nn.functional.softmax(values, dim=-1)
next_token_id = torch.multinomial(probs, num_samples=1)
return indices[next_token_id].item()
TopP
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
class TopPSampling:
def __init__(self, p: float):
self.p = p
def next_token(self, logits):
# sort the logits
sorted_logits, sorted_indices = torch.sort(logits, descending=True)
sorted_probs = torch.softmax(sorted_logits, dim=-1)
# compute cumulative probabilities
cum_probs = torch.cumsum(sorted_probs, dim=-1)
# create a mask indicating if cumulative probability is less than the top_p
valid_mask = cum_probs <= self.p
# sometimes the first token itself might have higher probability than the cumulative probability
# this is case, set the first one to be valid
if not valid_mask.any():
valid_mask[0] = True
# find the cutoff index
cutoff_index = torch.nonzero(valid_mask, as_tuple=False).max().item()
# get the token indices and their probabilities upto and including the cutoff index
valid_indices = sorted_indices[:cutoff_index+1]
# calculate the probabilities again using subset of logits
valid_probs = torch.softmax(sorted_logits[:cutoff_index+1], dim=-1)
next_token_id = torch.multinomial(valid_probs, num_samples=1)
return valid_indices[next_token_id].item()
The code below is a refactored version of the generate method that accepts different sampling strategies.
Click to expand code for generator method
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
def generate(gpt, sampler, tokenizer, initial_text=None, max_len: int=50, temperature=0.4):
input_ids = [tokenizer.cls_token_id]
if initial_text:
# tokenizer add SEP token at the end, do not include that one
input_ids = tokenizer(initial_text)['input_ids'][:-1] # type: ignore
gpt.eval()
while len(input_ids) < max_len:
with torch.no_grad():
logits = gpt(input_ids=torch.LongTensor(input_ids).unsqueeze(0))
# take the logits of the last token
logits = logits[0][-1] / temperature
next_token_id = sampler.next_token(logits=logits)
input_ids.append(next_token_id)
if next_token_id == tokenizer.sep_token_id:
break
return tokenizer.decode(input_ids)
from functools import partial
greedy = partial(generate, gpt=gpt, sampler=GreedySampling(), tokenizer=tokenizer)
topk = partial(generate, gpt=gpt, sampler=TopKSampling(k=10), tokenizer=tokenizer)
topp = partial(generate, gpt=gpt, sampler=TopPSampling(p=0.9), tokenizer=tokenizer)
Let’s try and generate a few texts using different sampling strategies. Please note that the model I used was the one I trained only on news dataset and has about 43 million parameters so the outputs are still kind of subpar. If you used a different model, you’ll probably see some good results.
1
2
3
4
5
initial_text = "Nvidia and microsoft"
temperature = 0.1
print(f"Greedy: {greedy(initial_text=initial_text, temperature=temperature)}")
print(f"TopK : {topk(initial_text=initial_text, temperature=temperature)}")
print(f"TopP : {topp(initial_text=initial_text, temperature=temperature)}")
1
2
3
Greedy: nvidia and microsoft join forces to develop protocols to the graphics chip maker is teaming up with microsoft to develop a new desktop computer that allows users to view their computers.
TopK : nvidia and microsoft join forces to develop protocols to the graphics software turbocadas in the past two months, the company is teaming up with its entertainment and microsoft to develop a custom graphics technology.
TopP : nvidia and microsoft join forces to develop new gpu for the gpu and the graphics engine is the latest in the world.
For the same initial text, when temperature is 0.9 allowing the model to be more creative, we get the following. Note that the output of Greedy approach does not change at all.
1
2
3
Greedy: nvidia and microsoft join forces to develop protocols to the graphics chip maker is teaming up with microsoft to develop a new desktop computer that allows users to view their computers.
TopK : nvidia and microsoft develop gpu for gp ( ziff davis ) ziff davis - the nvidia graphics processor has developed into the gpu of its turbocache conference, the companies said thursday.
TopP : nvidia and microsoft prepare to open content the graphics chip maker # 39 ; s december 7, 2004 - microsoft and cisco are working on a project to give governments access to its content management software.
Let’s change the temperature to a bit extreme value of 10. The output from TopP and TopK is completely garbage.
1
2
3
Greedy: nvidia and microsoft join forces to develop protocols to the graphics chip maker is teaming up with microsoft to develop a new desktop computer that allows users to view their computers.
TopK : nvidia and microsoft hope to push for a more positive release from the gpuquan tool will soon be called upping. it was also one of their features a great chance. that microsoft # 1
TopP : nvidia and microsoft extreme ponder planes knocking dipped believes32 & 350 abaivated foolishsibility harderrry face helping give strapped distributors containing 111 kilometer retail 134 officials electrified acres reagan trek relying liverpool tee fix delight settlers30
Conclusion
In this post we explored 3 ways of choosing next token when generating texts. As a summary, you should use lower temperature for precise answers and higher temperature for open ended generation. Generally Top-P and Top-K sampling methods are used and they can also be combined together. There are other strategies as well like Beam search which I didn’t discuss here.
If you are using models from HuggingFace, then refer to this post from HuggingFace for more details. You can also refer to this post: Generation Strategies for more details about how to configure the generation method. Models in HuggingFace support all kind of strategies so it is better to use those whenever you can.
I hope you found this useful. Please let me know if there are any errors.
This article is Part 5 in a 5-Part Understanding Transformers Architecture.




Comments